1. 다층 퍼셉트론 분류 모델(MLP)의 등장
퍼셉트론 분류 모델은 데이터 분포가 선형 분리 가능할 때만 결정 경계의 수렴을 보장한다는 한계가 있었습니다. 하지만, 다층 퍼셉트론 모델은 이러한 선형 분리가 불가능한 데이터 분포 문제를 해결했습니다. 퍼셉트론(Perceptron) 개념의 등장(Rosenblatt, 1958), 단층 퍼셉트론의 한계(Minsky & Papert, 1969), 그리고 역전파(Backpropagation) 알고리즘 개발(Rumelhart et al., 1986)을 순차적으로 살펴보면 선형 분리 문제 해결 과정을 파악할 수 있습니다.
1.1 퍼셉트론(Perceptron) 등장
다층 퍼셉트론 등장의 배경을 이해하기 위해, 초기 퍼셉트론 개념을 다룬 논문을 먼저 살펴보겠습니다.
1958년 Rosenblatt는 「The Perceptron: A probabilistic model for information storage and organization in the brain」이라는 논문에서 인간과 같은 고등 유기체(higher organisms)의 지각, 회상, 사고 능력을 이해하기 위한 세 가지 질문을 제시했습니다.
- 생물학적 시스템은 물리적 세계에 대한 정보를 어떻게 감지하거나 탐지하는가? (How is information about the physical world sensed, or detected, by the biological system?)
- 정보는 어떤 형태로 저장되거나 기억되는가? (In what form is information stored, or remembered?)
- 저장소나 기억 속에 담긴 정보는 인식과 행동에 어떻게 영향을 미치는가? (How does information contained in storage, or in memory, influence recognition and behavior?)
Rosenblatt(1958)는 신경계의 코드와 배선도(wiring diagram)를 이해하면 유기체가 무엇을 기억하는지 정확히 밝혀낼 수 있다고 주장했습니다. 뇌의 정보 처리 방식을 모방한 확률론적 모델인 퍼셉트론(perceptron)을 제시하여, 정보가 뇌에 어떻게 저장되고(기억), 저장된 정보가 인식과 행동에 어떻게 영향을 미치는지 퍼셉트론의 개념을 통해 설명하고자 했습니다.
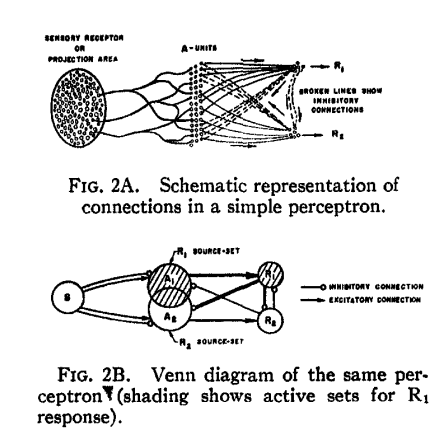
구체적으로, 기억이 뉴런 간에 연결(connection) 또는 경로의 형태로 저장된다는 연결주의(connectionist)를 제시했습니다. 뇌는 자극의 이미지를 직접 저장하는 대신, 특정 자극이 특정 반응을 유발하도록 신경망의 연결 강도가 변화하는 방식으로 학습한다는 것입니다. Rosenblatt(1958)가 주장한 퍼셉트론 모델은 세 부분으로 구성됩니다.
- 첫 번째, S-유닛(감각 유닛, Sensory units) 은 망막과 같이 외부 자극을 받아들이는 센서입니다.
- 두 번째, A-유닛(연합 유닛, Association units) 은 S-유닛으로부터 신호를 받아 처리하는 중간 단계에 위치하며, 이 유닛들은 S-유닛 및 다른 A-유닛들과 무작위로 연결되어 있습니다.
- 세 번째, R-유닛(반응 유닛, Response units) 은 A-유닛들로부터 신호를 받아 출력을 결정합니다.
학습은 A-유닛과 R-유닛의 연결 강도 및 A-유닛의 가치(value)를 조정함으로써 이루어집니다. 특정 자극에 대해 원하는 반응이 발생했을 때, 해당 반응에 기여한 A 유닛들의 가치(value)를 강화(증가)시킵니다. 이러한 가치 조정 방식에 따라 알파(α), 베타(β), 감마(γ) 시스템 세 가지를 비교했으며, 특히 활성 유닛이 비활성 유닛의 가치(value)를 빼앗아 전체 가치 총합을 일정하게 유지하는 감마(γ) 시스템의 역할이 중요하다고 보았습니다.
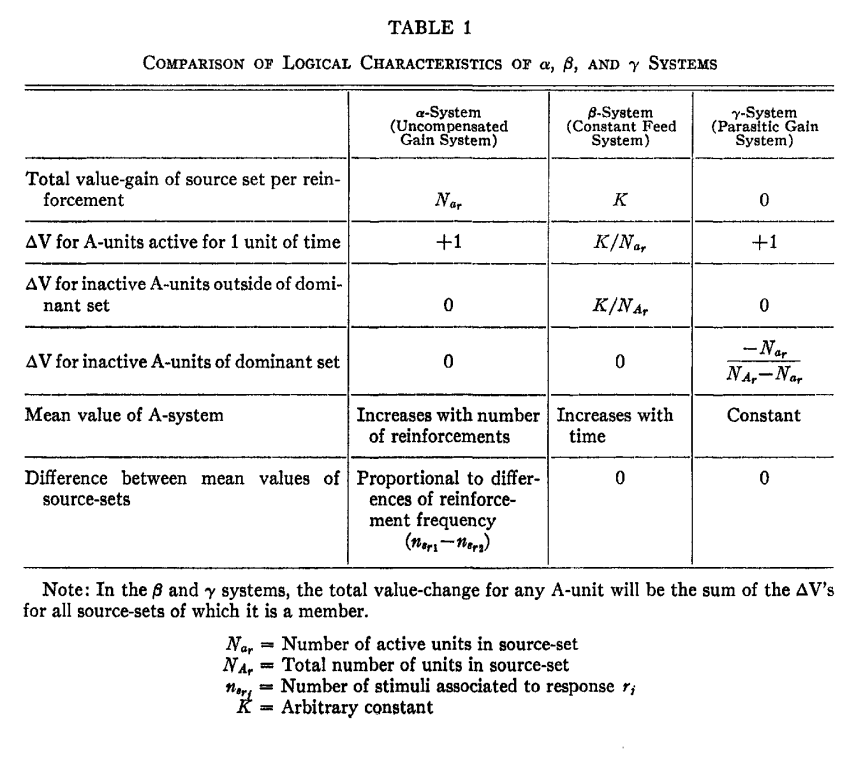
또한, 기억은 특정 뉴런 하나에 저장되는 것이 아니라 시스템 전체의 연결 강도에 분산되어 저장된다는 분산 기억을 주장하였습니다. 일반화 학습에 대해서도 제기하였는데, 가치 붕괴와 같은 특정 조건에서는 외부의 정답 지시 없이도 단순한 자극에 노출되는 것만으로 환경 내의 자극 클래스(사각형 또는 원)를 구별하는 자발적 개념 형성 능력을 보인다고 제시하였습니다. 보상과 처벌에 해당하는 긍정적/부정적 강화를 통해 시행착오 학습이 가능하다고 주장합니다. 하지만 퍼셉트론은 패턴 인식, 연상 학습, 선택적 주의 등은 가능하지만, A의 왼쪽에 있는 물체와 같이 자극 간의 관계를 추상화하는 고차원적 기능에는 한계를 보인다고 지적했습니다(Rosenblatt, 1958).
1.2 Parity 문제
Minsky와 Papert는 1969년에 「Perceptrons: An Introduction to Computational Geometry」라는 책을 출간했습니다. 이 책은 가장 단순한 학습 기계를 퍼셉트론이라고 정의했으며, 병렬 계산, 패턴 인식, 지식 표현, 학습과 관련하여 수학적으로 증명하였습니다.

Minsky & Papert(1969)는 단층 퍼셉트론이 패리티(Parity) 문제를 수학적으로 해결할 수 없음을 증명하였습니다. 패리티 문제란 ON 상태인 입력의 개수가 짝수인지 홀수인지를 판별하는 문제입니다.
패리티 함수(Parity Function)는 다음과 같이 정의됩니다.
정리(Theorem)는 다음과 같습니다.
패리티 문제의 대표적인 예시인 XOR 문제는 입력이 2개일 때의 홀수 판별 문제입니다. 패리티 함수는 R의 전체 크기와 동일한 차수(order)를 가집니다. 따라서 단층 퍼셉트론은 XOR 문제에서 차수가 2보다 작은 1이므로 패리티 문제를 해결할 수 없습니다.
구체적으로,
- (0, 0)은 켜진 입력이 없는 0인 짝수이기 때문에 패리티는 홀수이므로 0이라는 출력이 나오고,
- (0, 1)은 켜진 입력이 하나 있는 홀수이기 때문에 1이라는 출력이 나오고,
- (1, 0)은 켜진 입력이 하나 있는 홀수이기 때문에 1이라는 출력이 나오고,
- (1, 1)은 켜진 입력이 두 개 있는 짝수이기 때문에 0이라는 출력이 나옵니다.
Theorem은 전체 입력 공간을 \(|R|\) , 즉 총 입력 개수로 정의하므로, 총 입력이 2개(\(|R| = 2\) )인 경우 패리티 문제를 해결하려면 최소 2차의 감지기(\(\varphi\) )가 필요합니다. 이는 퍼셉트론 내부에 입력 2개를 동시에 처리할 수 있는 감지기(\(\varphi\) )가 있어야 함을 의미합니다.
당시의 퍼셉트론은 차수가 1로 매우 낮고 지역적 감지기들로 구성된 기계였기 때문에, XOR과 같은 고차원적인 문제를 풀 수 없다고 증명했습니다.
하지만, 1988년에 나온 확장판 에필로그에서는 PDP(Parallel Distributed Processing) 연구 그룹이 다층 퍼셉트론으로 문제를 해결한 사실(“multilayer linear threshold networks are potentially much more powerful than single layer perceptrons.”)을 언급하며, 다층 네트워크 구조가 문제 규모가 커질수록 계산 비용이 기하급수적으로 증가하고, 중간층 유닛들도 감바 퍼셉트론(Gamba Perceptron) 구조이며, 학습에 필요한 시도 횟수가 너무 많아 실용적이지 않다는 점을 지적했습니다. 즉, 다층 퍼셉트론으로 문제를 해결할 수 있지만 이에 대해 회의적인 입장을 드러냈습니다(Minsky & Papert, 1988).
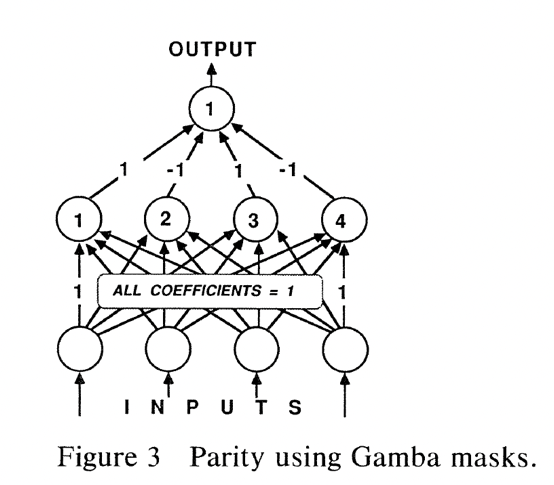
1.3 Back Propagation 등장
David Rumelhart, Geoffrey Hinton, Ronald Williams(1986)는 「Learning representations by back-propagating errors」라는 내용을 Nature에 발표했습니다. 이 논문은 다층 퍼셉트론 구조에서 중간층의 가중치를 학습시키는 방법에 대한 것으로, 은닉층의 개수와 상관없이 오차를 역전파시켜 모든 가중치를 자동으로 학습시킬 수 있는 수학적 방법을 제시했습니다.
학습 과정은 은닉 유닛(hidden units)을 도입하였습니다. 입력과 출력 행동에서 은닉 유닛들이 무엇을 표현(represent)하는지 구축하고 어떤 유닛이 활성화되어야 하는지가 학습 과정입니다. 순방향 전파(Forward Pass), 오차 최소화(경사 하강법), 역방향 전파(Backward Pass), 그리고 가중치 업데이트로 구성되며, 관련 수식은 다음과 같습니다.
순방향 전파(Forward Pass)
유닛 \(j\) 로 들어오는 총 입력 \(x_j\) 은 \(j\) 에 연결된 유닛들의 출력 \(y_i\) 과 이 연결들의 가중치 \(w_{ji}\) 의 선형 함수(linear function)입니다. 추가로, 각 유닛에는 편향(biases)을 부여합니다. 또한, 비선형 함수(non-linear function)인 실수 값의 \(y_j\) 이 있습니다.
오차 최소화(경사 하강법)
총 오차(total error) \(E\) 는 모든 사례(\(c\) )와 모든 출력 유닛(\(j\) )에 대해 실제 출력(\(y\) )와 원하는 정답(\(d\) )을 비교해서 계산한 제곱합 오차(Sum of Squared Errors, SSE)입니다.
오차 \(E\) 를 최소화하는 방법으로는 경사 하강법(gradient descent)을 사용하며, 각 가중치(\(w\) )에 대한 \(E\) 의 편도 함수(partial derivative), 즉, 기울기(\(\partial E / \partial w\) )를 계산합니다.
역방향 전파(Backward Pass)
역전파는 순방향, 역방향 패스로 두 번의 계산이 있습니다.
역방향 패스는 출력 유닛의 오차(\(\partial E / \partial y_j\) )를 계산하는 것으로 시작하며, 방정식 (3)을 미분하여 (4)를 얻습니다.
다음으로, 연쇄 법칙(chain rule)을 적용하여, 출력 유닛의 총 입력(\(x_j\) )이 오차에 미치는 영향(\(\partial E / \partial x_j\) )을 계산합니다. 방정식 (2)를 미분한 값을 사용하면 다음의 (5)번 식이 됩니다.
가중치(\(w_{ji}\) )가 오차에 미치는 영향(\(\partial E / \partial w_{ji}\) )은 연쇄 법칙에 따라 다음 (6)번 방정식과 같습니다.
이 오차를 이전 계층(유닛 \(i\) )으로 거꾸로 전파합니다. 유닛 \(i\) 의 오차는 (\(\partial E / \partial y_i\) ) 해당 유닛이 영향을 미친 모든 다음 층 유닛들(\(j\) )의 오차 기여도를 합산한 값입니다.
이처럼 마지막 층에서부터 맨 처음 층까지 반복적으로(recursively) 계산해서 모든 가중치의 기울기를 계산합니다.
가중치 업데이트
학습률(learning rate, epsilon, \(\epsilon\) )을 계산해서 가중치를 업데이트합니다.
방정식 (9)는 모멘텀(momentum)을 활용하여 방정식 (8)을 개선한 것으로, 현재의 기울기뿐만 아니라 직전의 가중치 변화량(\(\Delta w(t-1)\) )을 함께 고려하는 방식입니다. (알파값은 모멘텀 상수)
Rumelhart(1986)는 대칭성 감지, 가계도 문제와 같은 동형성 학습(기존 가계도의 부모-자녀 관계와 같이 다른 가계도에서도 해당 관계를 추론할 수 있는지 여부), 순환 네트워크 문제에 이러한 은닉층이 포함된 다층 레이어 구조를 적용하여 퍼셉트론이 내부 학습을 통해 문제를 해결할 수 있다고 논문에서 제시했습니다.
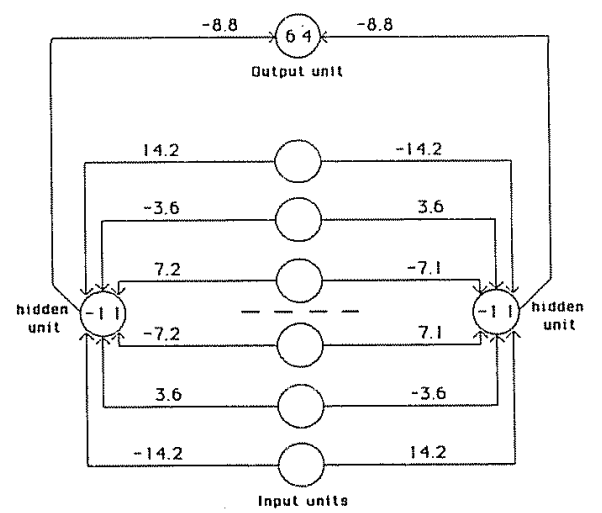
예를 들어, Rumelhart(1986)의 대칭성 문제를 살펴볼 수 있습니다. 이 문제는 입력층과 출력층만으로는 절대 해결할 수 없으며 반드시 중간에 은닉층(hidden layer)이 필요합니다. 역전파 알고리즘이 스스로 복잡한 은닉층의 가중치(1:2:4 비율)를 찾아내는 것을 볼 수 있습니다. 은닉 유닛(hidden unit)이 2개만 있어도 대칭성 문제를 해결할 수 있음이 확인되었습니다(Rumelhart, Hinton, Williams, 1986).
구체적으로, 해당 이미지는 입력 벡터의 좌우 대칭(mirror symmetry)을 감지하도록 학습한 네트워크를 보여줍니다. 입력 유닛에서 은닉 유닛으로 가는 선 위쪽에는 각 가중치가 적혀 있으며, 노드 안에는 편향(bias) 값이 약 -11로 설정되어 있습니다. 파라미터(parameter) 값은 \(\epsilon = 0.1\) 이고, \(\alpha = 0.9\) 이며, 초기 가중치는 무작위로 -0.3 ~ 0.3 사이로 설정했습니다. 입력이 2개가 들어오면 각 입력이 서로 대칭인지 아닌지 가중치를 곱하고 편향을 더하여 결정합니다. 예를 들어 입력 유닛이 (0, 0)일 때, 가중치는 14.2 × 0 + 0 × -14.2 - 11 = -11으로 음수가 되어 활성화 함수를 거쳐 비활성화 상태가 됩니다. 이 때 출력 유닛에서는 0 × -8.8 + 0 × -8.8 + 64 = 64라는 양의 수로 ‘on’이 출력됩니다(이는 (1, 1)이 입력될 때도 동일합니다). 입력 유닛이 (1, 0)으로 들어가 활성화 함수를 거쳐 은닉 유닛 중 하나가 ‘on’으로 출력되면 (1 × -8.8) + (0 × -8.8) + 64 = 55.2로 64보다 적은 숫자가 되어 출력 유닛에서 ‘off’로 나타납니다.
은닉 구조 및 가중치 업데이트를 통해 가계도 문제 역시 은닉 유닛이 단순 암기가 아닌 영국인과 이탈리안 가계도의 공통된 추상적인 구조(동형성)를 스스로 학습한다는 것, 순환망에도 적용할 수 있음을 확인할 수 있습니다. 주의할 점으로 모델이 학습할 때 전역 최소값(global minimum)이 아닌 지역 최소값(local minimum)에 빠져 학습이 멈출 수 있지만, Rumelhart(1986)는 경험상 네트워크에 연결(가중치)를 충분히 많이 만들어두면 이 문제는 거의 일어나지 않는다고 주장합니다.
종합하면, 다층 퍼셉트론(MultiLayer Perceptron; MLP)은 sigmoid, tanh, ReLU 등과 같은 비선형 활성화 함수를 적용하여 입력 공간을 비선형적으로 변환하는 방식을 제시합니다. 그리고 은닉 층(Hidden Layer)의 각 노드에서 서로 다른 선형 결정 경계를 학습하여, 입력을 고차원 특징 공간으로 매핑하는 차원 확장을 수행합니다. 이는 원래 공간에서는 선형 분리가 불가능한 데이터 분포도 은닉층을 통과하며 고차원 공간에서 선형 분리가 가능하도록 해결하는 원리입니다.
2. 다층 퍼셉트론 분류 모델의 구조
다층 퍼셉트론 분류 모델의 구조의 예시로 XOR을 풀어보겠습니다. Ian Goodfellow(2016)가 제시한 XOR 문제 해결을 위한 다층 퍼셉트론 분류 모델의 구조는 다음과 같습니다.
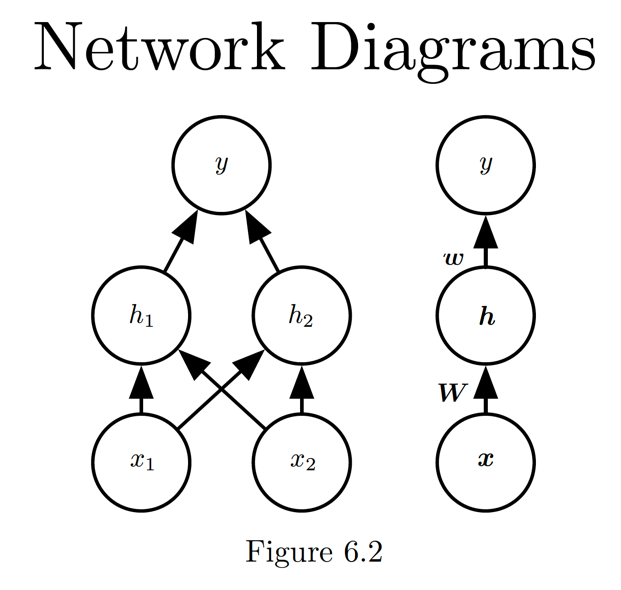
XOR 문제를 풀기 위한 신경망을 두 가지 스타일로 표현할 수 있습니다. 그림 6의 왼쪽은 신경망의 각 입력 노드들, 은닉 노드들을 표현한 것이고, 오른쪽은 간결하게 표현한 스타일입니다.
Goodfellow(2016)는 신경망 공식을 위와 같이 정의했습니다. 매개변수 \(W, c, w, b\) 는 각 층의 가중치, 편향, 가중치, 편향값을 나타냅니다. 추가적으로 Goodfellow(2016)는 ReLU 활성화 함수(\(g(z) = \max\lbrace 0, z \rbrace\) )가 현대 신경망에서 기본적으로 권장된다고 제시합니다.
XOR 문제를 풀기 위해, 매개변수 \(W = [[1, 1], [1, 1]]\) 로 설정하여 입력 공간을 변환하는데, 해당 가중치는 두 입력의 합을 계산합니다(\(x_1 + x_2\) ).
매개변수 \(c = [0, -1]\) 로 각 은닉 뉴런의 편향을 다르게 설정하였습니다. 첫 번째 은닉 뉴런은 편향이 0이므로, \(h_1 = \text{ReLU}(x_1 + x_2 + 0)\) 이 되어 입력의 합을 봅니다. 따라서 (0, 0), (0, 1), (1, 0), (1, 1) 입력 값은 첫 번째 은닉 뉴런을 통과한 결과 값으로 0, 1, 1, 2가 나옵니다.
두 번째 은닉 뉴런은 \(h_2 = \text{ReLU}(x_1 + x_2 - 1)\) 으로 편향으로 -1이 들어가 임계값이 1이 됩니다. 따라서 (0, 0), (0, 1), (1, 0), (1, 1) 입력 값은 두 번째 은닉 뉴런을 통과한 결과 값으로 0, 0, 0, 1이 나옵니다. 즉, 입력 값이 모두 1인 경우에만 두 번째 은닉 뉴런이 활성화되는 것을 알 수 있습니다.
매개변수 \(w = [1, -2]\) 로 설정하고 편향 \(b\) 는 0입니다. 결과값 \(y\) 는 \(h_1 - 2 h_2 + 0\) 으로 나타낼 수 있고 \([1, -2]\) 로 가중치가 설정된 이유는 결과값을 0 또는 1로 제한하기 때문입니다.
구체적으로 계산해 보면 다음과 같습니다.
- 입력 [0, 0]은 가중치 행렬이 곱해져서 [0, 0]이 되고, 편향(bias) 값인 \(c\) 를 더하면 [0, -1]이 됩니다. ReLU 함수(\(f(z) = \max\lbrace 0, z \rbrace\) )를 거치면 [0, 0]이 되며, 최종 결과값은 \(y = 0 - 2 \times 0 + 0 = 0\) 이 나옵니다.
- 입력 [0, 1]은 가중치 행렬 \(W\) ([[1,1], [1, 1]])를 곱하면 [1, 1]이 되고, 편향 \(c\) 를 더하면 [1, 0]이 됩니다. ReLU를 통과해도 [1, 0]이며, 최종 결과값은 \(y = 1 - 2 \times 0 + 0 = 1\) 이 나옵니다. 입력 [1, 0]도 동일한 결과가 나옵니다.
- 입력 [1, 1]은 가중치 행렬 \(W\) 이 곱해지면 [2, 2]가 되고, 편향 \(c\) 를 더하면 [2, 1]이 됩니다. ReLU를 통과해도 [2, 1]이며, 최종 결과값은 \(y = 2 - 2 \times 1 + 0 = 0\) 이 나옵니다.
이처럼 최종 출력은 [0, 1, 1, 0]이 되어 선형 분리할 수 없었던 XOR 문제가 해결되는 것을 확인할 수 있습니다.
추가로, 이러한 다층 퍼셉트론 모델 구조를 코드로 구현할 수 있습니다.
class XORNetwork:
def __init__(self):
self.W1 = np.array([[1, 1], [1, 1]]) # 첫 번째 층 가중치 (2x2)
self.c = np.array([0, -1]) # 첫 번째 층 편향
self.w2 = np.array([1, -2]) # 두 번째 층 가중치 (2x1)
self.b = 0 # 두 번째 층 편향
def relu(self, x):
return np.maximum(0, x) # ReLU 함수
def forward(self, X):
z1 = np.dot(X, self.W1) + self.c # 첫 번째 층 구현 z1 = XW + c
h1 = self.relu(z1) # 활성화 함수 ReLU 통과
y = np.dot(h1, self.w2) + self.b # 두 번째 층 출력값 y = h1 * w2 + b
return y # output 결과값
입력 값인 X를 넣은 후 출력 과정은 다음과 같습니다.
# XOR 입력
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
# 계산 과정 상세
입력 (0,0):
z = [0, 0] @ [[1,1],[1,1]] + [0,-1] = [ 0, -1]
h = ReLU([ 0, -1]) = [0, 0] # hidden layer
y = [0, 0] @ [1,-2] + 0 = 0
입력 (0,1):
z = [0, 1] @ [[1,1],[1,1]] + [0,-1] = [1, 0]
h = ReLU([1, 0]) = [1, 0] # hidden layer
y = [1, 0] @ [1,-2] + 0 = 1
입력 (1,0):
z = [1, 0] @ [[1,1],[1,1]] + [0,-1] = [1, 0]
h = ReLU([1, 0]) = [1, 0] # hidden layer
y = [1, 0] @ [1,-2] + 0 = 1
입력 (1,1):
z = [1, 1] @ [[1,1],[1,1]] + [0,-1] = [2, 1]
h = ReLU([2, 1]) = [2, 1] # hidden layer
y = [2, 1] @ [1,-2] + 0 = 0
시각적으로 표현하면 \(x_1, x_2\) 의 원래 공간은 선형 분리가 불가능했습니다. ReLU 활성화 함수를 활용해 은닉층 \(h_1, h_2\) 으로 변환된 공간은 다음과 같이 선형 분리가 가능하도록 나뉘어집니다.
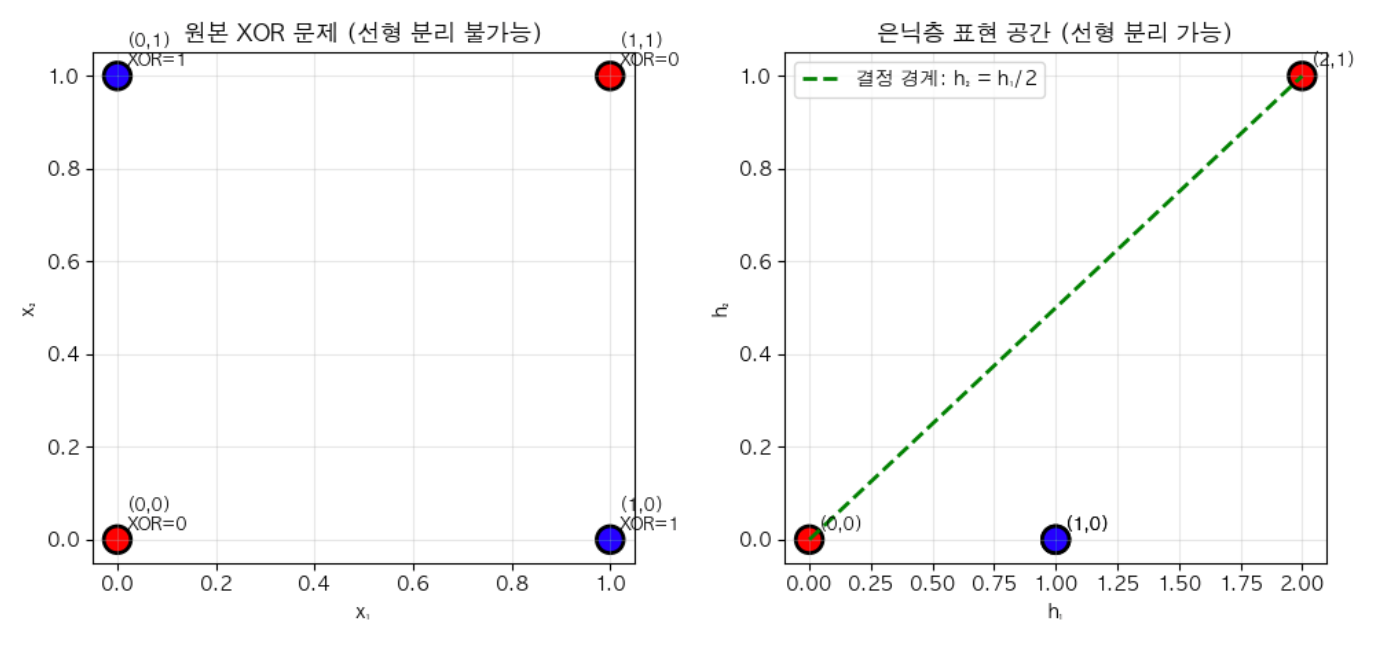
이와 같이 입력층, 은닉층 1개, 출력층 1개로 구성된 다층 퍼셉트론 모델 구조를 작성하여 오차가 0인 깔끔한 답이 산출되었습니다. 현실의 문제들은 좀 더 복잡하기 때문에 이처럼 정확하고 깔끔한 값이 나오는 경우는 거의 없습니다. 하지만, XOR 문제를 통해 단순 퍼셉트론에서 은닉층을 추가하고, ReLU와 같은 비선형 활성화 함수를 통해 선형 공간을 변환하는 과정을 살펴보고 가중치와 편향 값을 조절하여 문제를 해결하는 원리를 직접 구현하고 결과로 확인할 수 있었습니다.
3. 개인적인 소견
Minsky와 Papert가 예견한 다층 퍼셉트론의 계산 비용의 증가는 2025년 말 현재에도 여전히 유효한 한계입니다. Rumelhart의 역전파 알고리즘이 GPU, TPU 등 하드웨어의 발전, 막대한 자원 투입과 결합하여 이 문제를 표면적으로 우회한 듯 보이나, 그 이면에는 막대한 전력과 비용이 소모됩니다. 이는 Rumelhart가 자신이 만든 퍼셉트론 구조는 ’neuron-like’일 뿐 ’neuron’이 아니라고 지적했듯이, 생물학적 뇌의 효율성을 모방하려던 초기 목표와는 거리가 멉니다.
현재의 인공신경망이 탁월한 성능을 보이는 것은 사실입니다. 그런데 약 20와트의 전력으로 인간의 뇌가 수행하는 효율적인 학습 방식은 여전히 미지의 영역입니다. 뇌는 선택적 주의, 작업 기억, 망각, 단기 기억, 장기 기억, 정서 기억 등 복합적인 기제를 통해 현재 퍼셉트론이 학습하는 방식과는 다른 방식으로 정보를 처리하고 학습하는 것으로 보입니다. 뇌의 작동 원리를 모방하려는 시도는 계속되고 있으나, 그 핵심 원리는 아직 밝혀지지 않았습니다.
결국, GPU 성능에 의존하는 현재의 접근 방식은 한계에 부딪힐 것입니다. 인공지능 분야의 진정한 발전을 위해서는 퍼셉트론이 수많은 은닉층 연결과 끝없는 가중치 계산을 통해 이루어진 학습 방식의 비효율성을 극복하는 문제가 필수 과제라고 생각합니다.
Reference
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Minsky, M., & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
- Rosenblatt, F. (1958). “The perceptron: A probabilistic model for information storage and organization in the brain.” Psychological Review, 65(6), 386-408.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). “Learning representations by back-propagating errors.” Nature, 323(6088), 533-536.